

OCRによる全文検索とメタデータ検索の比較検証
デジタルアーカイブの環境下でコンテンツを検索する場合の方法として、
全文検索とメタデータ検索といった方法があります。
今回はOCR処理による全文検索とメタデータによる検索について、
それぞれの特徴やメリット・デメリットなどについてご紹介します。
目次[非表示]
OCRとは
OCR(Optical Character Recognition)とは、
スキャナなどで読み込んだようなラスターデータを、
文字データとしてテキスト化する技術です。
最近では有能なOCRソフトが開発されて流通しており、
デジタルアーカイブの世界においても、
これまで叶わなかったテキストによる全文検索が可能になりました。
最近ではAI-OCRといった技術の進展により、
これまで人の手による作業で読み込ませていたテキスト化するためのルールを、
AIを通じて学習させ、より正確な文字認識が可能になりつつあります。
例えば国立国会図書館が開発したNDLOCRは、
書籍や雑誌などの画像データから本文のテキストデータを作成できるOCRプログラムで、
明治~昭和期の古い資料や独特なレイアウトにも対応しています。
これはNDLが提供する「国立国会図書館デジタルコレクション」で利用可能です。
国立国会図書館デジタルコレクション
https://dl.ndl.go.jp/ja/
OCRはデジタルアーカイブの世界において、
これまでヒットしなかったような文献や資料に辿り着くことを可能にし、
利用者の利便性を飛躍的に高めています。
OCRにおける文字認識の精度
先述のとおりOCRの技術は加速的に進化していますが、
どんなOCRソフトであっても100%の文字認識が保証されているわけではありません。
様々な要因により認識率は左右されます。
認識精度に影響を与える要因には、次のようなものがあります。
・手書きか活字か
手書きは活字に比べて認識率は低下します。
しかし最近では、手書きに強いOCRソフトも存在します。
・旧字か新字か
旧字は新字に比べて認識率は低下します。
しかし手書き同様、旧字を得意とするOCRソフトも存在します。
・解像度
解像度が高いほど認識率は向上します。
300dpi~600dpiは確保するとよいでしょう。
・文字以外の写真や表、グラフなどの有無
OCRはレイアウトを解析した後、文字に分けるという処理をします。
当然文字のみの資料のほうがコンピュータも仕分けがしやすいため、
文字と写真、グラフなどが混在すると認識率は低下します。
・縦書きか横書きか、あるいは混在か
OCRはレイアウトを解析した後、行を探すという処理をします。
当然横書きか縦書きか統一されている資料の方がコンピュータも仕分けがしやすいため、
縦書きや横書きが混在していると認識率は低下します。
・手動認識か自動認識か
OCRソフトを自動で走らせて全文を認識する処理に比べ、
認識する範囲を手動で指定して認識するほうが認識率は高まります。
レイアウト解析や行を探すというコンピュータへの負荷が軽減されるためです。
・画像データの品質
解像度だけでなく、画像の歪みやたわみなどがあると、
文字の認識率は低下します。
このように様々な要因によって、
OCRの認識精度は左右されます。
当社では対象資料の特性に応じて、
最適なOCRソフトを使用してテキスト化しています。
OCRによるテキスト化事例:東京海上日動火災保険株式会社さま
メタデータとは
メタデータとは、資料を特定するために資料に紐づけた情報です。
資料が作成された年代や作成者(著者)、形状、保管場所、資料の内容説明などの情報を与えてあげることで、
資料の管理者は保有資料が一覧化されて全体を把握することができるとともに、
目録的な役割も果たします。
そして利用者は、閲覧・利用したい資料を特定することが可能になります。
メタデータの作成方法は主に手入力になります。
メタデータは正確性が求められるためです。
資料内の特定の場所に著者名があるなどと言った場合は、
著者の項目だけ、先に述べたOCRの技術を使ってテキスト化するといった複合的な方法もありますが、
手入力のほうがOCRに比べて正確性は安定しているといえます。
OCRによる読み取りが高確率でできるという検証が済んでいる場合は、
効率化できるOCR処理を選択してもよいと思います。
しかしOCRによる精度が担保されていない場合、
特に確実にヒットさせたいタイトルや著者名と言った項目は、
手入力でメタデータを作成し、利用者が確実にヒットできるようにするとよいでしょう。
またメタデータの正確性を確保するためには、
作成ルール(入力ルール)を決めておくことも必要です。
例えば、
・作成日の表記を西暦とするか、和暦とするか
・サイズの単位をcmで表記するか、mmで表記するか
・資料の種類の名称どのように分類するか(書籍、フィルム、巻物など)
などです。
これらの表記は一貫性を確保することがポイントです。
そして不明・不確かな情報は入力しないこと、などといったルールも決めておきます。
こうしたメタデータの入力手順や留意点は、こちらの記事をご参照ください。
メタデータの項目は、デジタルアーカイブの対象となる資料によって異なるところがありますので、こちらに参考リンクを掲載します。
関係省庁等連絡会・実務者協議会(事務局:内閣府知的財産戦略推進事務局)
『デジタルアーカイブの構築・共有・活用ガイドライン』
https://www.kantei.go.jp/jp/singi/titeki2/digitalarchive_kyougikai/guideline.pdf
国立国会図書館ダブリンコアメタデータ記述(DC-NDL)解説
https://www.ndl.go.jp/jp/dlib/standards/meta/about_dcndl.html
全文検索とメタデータ検索の比較
ここまでの内容を踏まえて、
OCRで抽出したテキストデータによる全文検索と、
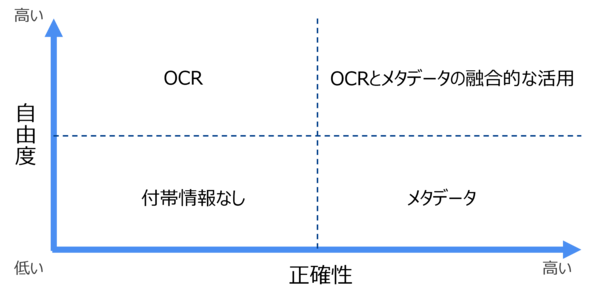
メタデータによる検索について比較してみると、概略は次の表のようになります。

全文検索は検索に対する自由度が高い一方、
検索ワードによってはノイズが大量に発生してしまうことや、
文字の認識率に検索精度左右されるなど、メタデータに比べると正確性に不安が残ります。
メタデータはテキスト化された文字は正確にヒットさせることができますが、
テキストが入力されていなければヒットしないため、
設定したキーワードによっては利用者の自由度が狭まってしまう可能性があります。
利用者の視点から、
資料のタイトルや作成者、作成機関、内容、注記、件名などと関連するキーワードを、
どのように設定するかがポイントとなるでしょう。
メタデータの主題や件名、キーワードに関する記事はこちらをご参照ください。
まとめ
OCRとメタデータにはメリット・デメリットがあると同時に、
検索の自由度・正確性の観点からも、得意分野が異なります。
メタデータで正確性を確保しながら、
OCRによって利用者の自由な発想で検索できるようにするなど、
両者を融合的に活用して利便性を高めましょう。
デジタルアーカイブに関する参考資料はこちら!↓

※参考記事











